在全球半导体产业受困于光刻机“卡脖子”的当下,北京大学科研团队的一项突破性成果引发行业震动。今年10月,由孙仲、蔡一茂、王宗巍等教授率领的团队成功研制出基于阻变存储器的高精度模拟矩阵计算芯片,不仅首次将模拟计算精度提升至24位定点精度,更实现了在28纳米及以上成熟工艺量产,为绕开高端光刻机限制开辟了全新技术路径。这一突破并非对传统数字芯片的微小改良,而是对计算范式的重构,为中国在算力竞赛中实现换道超车提供了可能。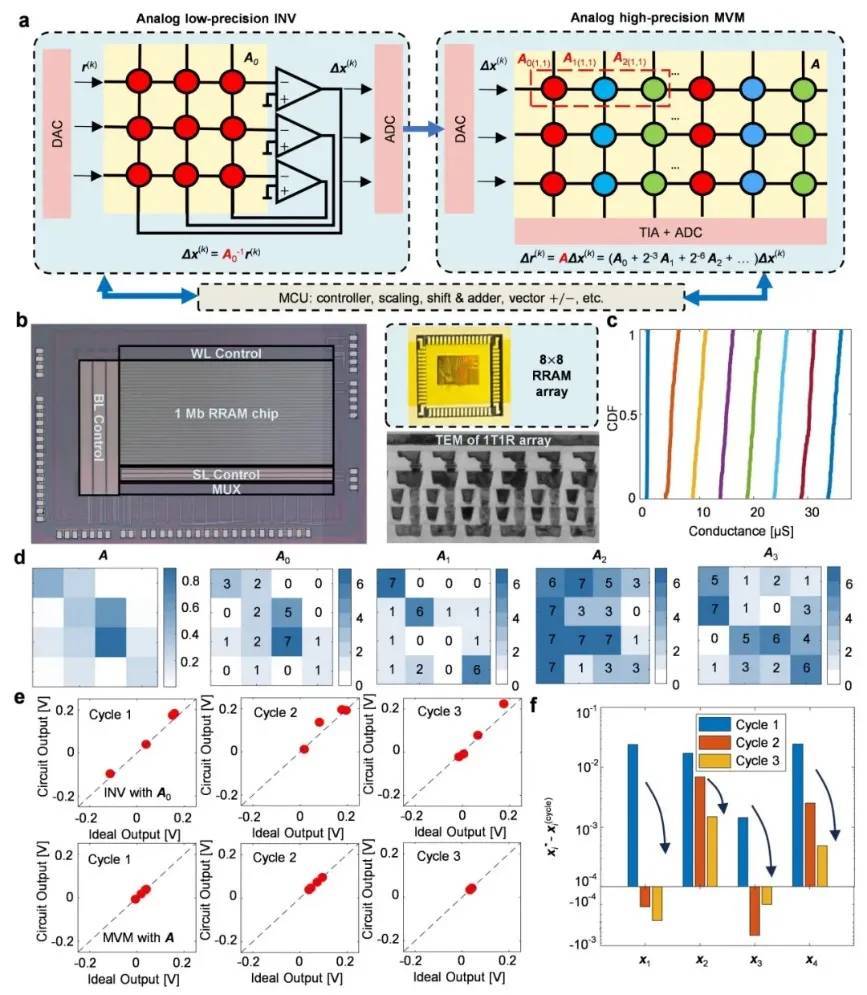
传统芯片产业高度依赖光刻机的精密加工能力,尤其是极紫外光刻机的技术垄断,让先进制程芯片的研发生产备受制约。而北大团队的创新之处,在于跳出了数字计算的固有框架,重拾曾因精度瓶颈被淘汰的模拟计算技术并实现升级。与数字芯片需将所有数据编码为0和1再通过逻辑门运算不同,模拟计算直接利用物理定律完成运算,如通过电压、电流等物理量直接对应数学数值,无需中间“翻译”环节,在能效和速度上具备先天优势。此前模拟计算的致命短板是精度不足,1%的相对误差会导致大规模计算中误差指数级累积,而北大团队通过器件、电路与算法的协同创新,将相对误差压降至千万分之一,精度提升5个数量级,彻底解决了这一世纪难题。

这款新型芯片的核心价值,既体现在技术突破上,更彰显于产业应用的可行性。从技术原理看,团队采用阻变存储器作为核心器件,其可编程的电阻特性实现了“存算一体”,避免了传统冯·诺依曼架构中计算与存储分离的效能损耗;通过原创电路设计与迭代优化算法,仅需数次迭代即可将计算精度逼近数字芯片的浮点32位水平,能完美适配AI大模型训练、6G通信、具身智能等前沿场景的算力需求。更关键的是,该芯片无需依赖高端光刻机,依托现有成熟制程即可量产,大幅降低了对外部设备的依赖,破解了“无高端光刻机就造不出先进芯片”的困局。
在摩尔定律渐趋终结的背景下,传统数字芯片通过堆叠晶体管提升算力的路径已陷入能耗与成本的双重困境。当前AI大模型训练动辄需要万卡级算力集群,能耗与碳排放呈指数级上升,与“双碳”目标相悖。北大新型模拟芯片则凭借物理定律直接运算的特性,能耗较数字芯片降低数个量级,为解决算力与能耗的矛盾提供了新方案。业内专家指出,该技术不仅是对现有算力体系的补充,更有望在AI二阶训练等核心场景中替代部分GPU功能,改变全球算力格局。

当然,从实验室成果到规模化量产仍需跨越产业化障碍,如阻变存储器的工艺优化、产业链协同配套等。但这一突破的意义已远超技术本身,它证明中国在半导体领域无需局限于传统赛道的追赶,通过计算范式创新完全可以开辟新赛道。随着这项技术的进一步落地,未来智能设备有望形成“CPU统筹+模拟芯片专攻高强度运算”的协同架构,而中国也将在全球半导体产业的技术变革中,从跟跑者转变为规则制定的参与者。北大团队的探索,为突破技术封锁提供了重要启示:核心技术的突破往往源于思维的突破,换道而行或许正是破解“卡脖子”困境的关键。




